Complex Event Modelling in Elasticsearch⚓︎
Executive Summary⚓︎
This guide walks through the theory and practice of modelling complex data events in elasticsearch for speed and limited data storage, with the aim of providing a single event level datastore that is able to support both event and party analysis. It is targeted at data architects designing how data should be modelled in elasticsearch for general business intelligence as well as fraud analysis.
Modelling Theory⚓︎
Historically our primary approach to store and analyse complex real world events has been relational database tables. Complex events are generally modelled in the below structure leveraging foreign key relationships to represent the context of the characteristics within the original event. This approach attempts to model all events in a way that standardises the location of common attributes.
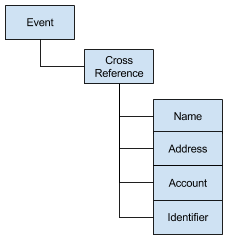
When a new event comes in after some standardisation and embellishment, a check is made to determine if the name, address, account and/or ids already exist in the data holdings ready. If they do then a link in the cross reference table is made to the existing record, else a new record inserted in the Name, Address, Account or Id table (with a new primary key). The above approach affords great performance when doing a search for one particular characteristic because we only have standardised and unique data stored in the Name, Address, Account and Identifier tables. Similarly given a specific characteristic key it is fast to perform a search on the cross reference table to find all of the other characters associated to a given characteristic key. However this approach creates some challenges as we need to maintain transactional integrity of these tables (with blocking locks) - which at the end of the day means it’s hard to get this approach to scale.
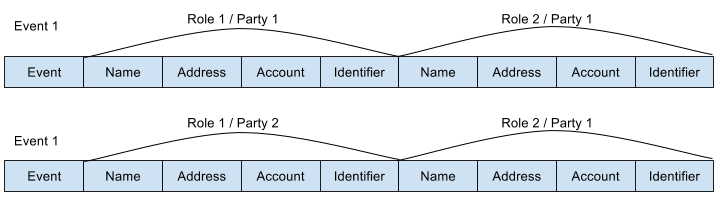
An alternative to the above approach is to flatten out the data model. Basically we remove all of the database keys and name the columns based on the party characteristics.

This allows the loading and storage of the data to be distributed and scaled easily as their is no dependency on the data stored in the datastore when loading events. However it means querying and dealing with the results of queries is more complex as party details are not stored uniquely. It also results in massively wide rows if you dataset has multiple parties performing the same role or multiple groups of characteristics of the same type for one party (e.g. main and postal address).
A partially flatten data model can be leveraged to reduce the number of columns where the dataset has repeating groups of parties and characteristics (it’s very similar to joining all of the tables together in the relational data model). This approach is obviously inefficient as there is mass data duplication, and leads to the need for further logic to de-duplicate query results.
When designing a new and large analytical application we wondered if there were any new technical options available that provided the best of both approaches described above. Specifically; - Supported logically simple searches (i.e. storage of common attributes in the same logical location in the data model) while limiting data redundancy similar to the relational data model, and - Allowed for scalable distributed loading and searching performance similar to the flatten data model. And ideally allowed for aggregated analysis of party details (associated to the underlying events) without the need to maintain a derived data source.
Elasticsearch promised to be able to meet these requirement so we ran up a PoC. The majority of the work involved in setting up the PoC was setting up the schema (or mapping in elasticsearch terms). Yeah elasticsearch is schema-less - however if you actually want to use it for anything production like you are going to need to define a mapping).
We modelled our events in elasticsearch using the below data model. It's very similar to the traditional relational model however it breaks apart role and party to allow for multiple parties to perform the same role for a given event (e.g. two people buying a house together).
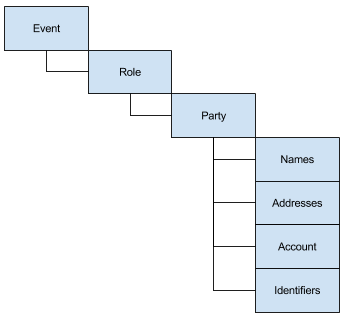
To support this product model in elasticsearch we relied heavily on the nested mapping data type. What this essentially does is tell elasticsearch to create a new “sub” document for each level in the data model below the highest level. The below table illustrates how one event explodes to multiple documents when stored in elasticsearch.
| eventId | eventDate | roleType | partySequence | partyType | fullName | StreeAddress |
|---|---|---|---|---|---|---|
| 1 | 2009-01-01 | |||||
| Payer | ||||||
| 1 | individual | |||||
| James Brown | ||||||
| 12 Wood St | ||||||
| 2 | individual | |||||
| Bill Brown | ||||||
| Billy Brown | ||||||
| 1 High St | ||||||
| Payee | ||||||
| 1 | individual | |||||
| Mark Rich | ||||||
| 22 Low St |
While there are many documents created, elasticsearch manages them all as one logical document so if you delete/upsert the event all of the nested documents are also deleted/upserted.
This elasticsearch configuration exceeded our expectations in relation to distributed loading/querying and storage of common attributes together for simplified searching. Elasticsearch was also able to support the aggregated analysis of party details without the need to maintain a derived data source.
The below worked example is the "generified" version of what we setup within our PoC, it has been provided in the hope that others can learn from what we have done.
Modelling Example⚓︎
In this section of the guide we provide a worked example of how to; - Create the above data model in elasticsearch, - Populate it with sample data, and - Query and aggregate event level attributes. - Query and aggregate party level attributes.
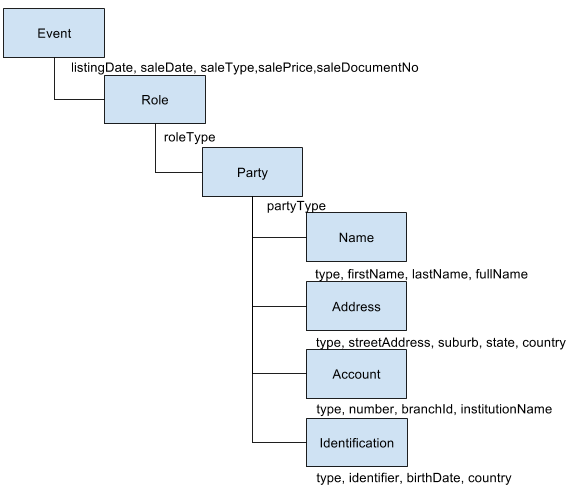
This example assumes that we are modelling real estate transactions. The basic data model has been fleshed out below. Noting that each name, address, account and id has a type (e.g. a party may have a main and a postal address).
Loading the Sample Data⚓︎
It is assumed that you have an elasticsearch cluster running version 6 (beta 2 or up) if not go here → https://www.elastic.co/guide/en/elasticsearch/reference/current/installation.html). The below scripts use the curl command to interact with elasticsearch they assume you are running these commands on the local machine (i.e. localhost) and that the elasticsearch cluster has authentication turned off (if you have authentication turned on you can submit in your username and password with curl requests).
Some sample data matching the above example has been saved into the repository. However before loading, elasticsearch needs to be told how you want the data stored - this is called a mapping. The mapping for the sample data can be posted into elastic with the following command.
<./load-sample-data-using-curl>curl -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/real-estate-sales?pretty' -d @real-estate-sales.mapping.json
The key setting in the mapping that will allow us to analyse each level of the data model is called nesting. What this setting does behind the scenes is store the data in that section of the mapping as a separate document, which we can then target with particular queries.
Once the mapping has been loaded successfully the sample data can be loaded using the following command
<./load-sample-data-using-curl>curl -H 'Content-Type: application/x-ndjson' -XPOST 'http://localhost:9200/real-estate-sales/sales/_bulk?pretty' --data-binary @real-estate-sales.sample.data.json
Simple Queries (event level characteristics)⚓︎
Querying attributes at the top level of the document structure is super simple. An example has been provided below. It searches for events with a transactionType of "Bank Initiated". You will note that it is using the transactionType.keyword field – which basically means it's doing an exact phase match rather than a terms search. The query also illustrates; how to set the amount of data returned (default is 10 records), limit the fields returned, and sort the response data.
<./dsl-queries>curl -H 'Content-Type: application/json' -XGET 'http://localhost:9200/real-estate-sales/_search?pretty' -d @event-level-search.dsl
Simple Aggregations (event level characteristics)⚓︎
Aggregations at the top level of the document structure is also super simple. An example has been provided below. It aggregates the number of sales per month. You'll note that the response size has been set to zero, the reason being is that if you do not set the size to zero, the response will include the requested aggregation and ten documents.
<./dsl-queries>curl -H 'Content-Type: application/json' -XGET 'http://localhost:9200/real-estate-sales/_search?pretty' -d @sales-per-month-aggregation.dsl
A terms aggregation has been provided below, it breaks down the number of sales by transaction type. Term aggregations are similar to group bys in SQL, however they are not exactly the same, due to elasticsearch’s distributed architecture effectively a SQL group by is performed on each shard in the cluster and the highest frequency results on each cluster are consolidated and then these results are aggregated.
<./dsl-queries>curl -H 'Content-Type: application/json' -XGET 'http://localhost:9200/real-estate-sales/_search?pretty' -d @transaction-types-aggregration.dsl
Nesting Queries⚓︎
Nested queries allow you to search the nested documents that were created as a result of the nested mapping. Using the inner-hits option and excluding _source from the response you can search each level of the nested hierarchy, as if they were stored separately.
Nested Example 1 - The below query searches for all parties with a specific name and address. This query uses the 'must' parameter which means to match the document must have both of the characteristics specified.
<./dsl-queries>curl -H 'Content-Type: application/json' -XGET 'http://localhost:9200/real-estate-sales/_search?pretty' --data "@inner-hits-name-address-search.dsl"
The thing to remember is that you get one result for each nested document that the name and address combination were on, what this means is that the results are not unique (in the partySearch section below we describe how to get unique hits returned).
Nested Example 2 - The below query searches for all parties with at least two of the three search criterias across ; name, address and identification. This query uses the 'should' parameter and the minimum should match parameter to narrow the results to only parties that have two of the three specified criteria.
<./dsl-queries>curl -H 'Content-Type: application/json' -XGET 'http://localhost:9200/real-estate-sales/_search?pretty' --data "@inner-hits-name-address-id-search.dsl"
Nesting Aggregations⚓︎
Nested aggregations can be performed in the same way that simple aggregations are performed. An example has been provided below of the most common first names within the sample dataset. The terms aggregation includes the parameters - 'size' which limits the results to the highest frequency names (noting the above limitations in relation to how term aggregations are executed), and - 'shard_size' which is used to set how many results are returned from each shard before the results are consolidated.
<./dsl-queries>curl -H 'Content-Type: application/json' -XGET 'http://localhost:9200/real-estate-sales/_search?pretty' --data "@./first-name-term-aggregration.dsl"
Writing your search query within the aggregation section of your request limits the nested documents to be aggregated (if you apply the search query in the query section of your request this will pass all of the nested documents present on events that meet the search criteria to the aggregation - which is not what you want). The below query illustrates how to perform a filter criteria within a nested aggregation.
<./dsl-queries>curl -H 'Content-Type: application/json' -XGET 'http://localhost:9200/real-estate-sales/_search?pretty' --data "@./most-common-buyer-name.dsl"
Sometimes you want to filter the results based on characteristic deep within the hierarchy, but then perform an aggregation higher up in the hierarchy. Elasticsearch provides us with the reverse nesting aggregation to perform this task. The below query illustrates this function. In this query we want to perform a role level aggregation (term aggregation on role.type) based on the identification level characteristic (identification country equals CN).
<./dsl-queries>curl -H 'Content-Type: application/json' -XGET 'http://localhost:9200/real-estate-sales/_search?pretty' --data "@identification-level-filter-with-role-level-aggregration.dsl"
partySearch⚓︎
Above we learnt how to search for parties with specific characteristics, however as mentioned these queries do not return unique results. Using elasticsearch’s aggregation functionality it is possible to aggregate these documents to return unique hits and a count of total instances. The below query searches for parties with at least two of the characteristics searched for, and aggregates the details of the characteristics of the parties that match this search criteria. You will note that the query returns other addresses, accounts and ids that were not within the original request however are likely to be linked to the party we searched for as these parties share two common attributes with the party we searched for.
<./dsl-queries>curl -H 'Content-Type: application/json' -XGET 'http://localhost:9200/real-estate-sales/_search?pretty' --data "@partySearch-name-address-and-id.dsl"
Using what we have learnt about reverse aggregations it is also possible to get statistics in relation to the events that these parties are contained within. The below query filters the role.party nested documents based on the supplied characteristics, aggregates to finds the unique characteristics then navigates to the top level document to sum the sale amount for each characteristic.
<./dsl-queries>curl -H 'Content-Type: application/json' -XGET 'http://localhost:9200/real-estate-sales/_search?pretty' --data "@partySearch-name-address-and-id-with-reverse-nesting.dsl"
Search Template For partySearch⚓︎
So now we know how to write elasticsearch queries however they are a bit hard to throw together when you know nothing about elasticsearch or how the data is stored. In other words our frontend developers just want a simple API - they don’t want to know the details of the data structure in elasticsearch.
This is where search templates come in they allow us to hide the complexity of the elastic index structure and query structure from consumers. Basically consumers just need to provide their input parameters and elasticsearch takes care of the required search.
Search Templates can either be saved to file or posted directly into elasticsearch (we will post in our examples). The below command posts in a search template for the partySearch described in the above section.
<./dsl-queries>curl -H 'Content-Type: application/json' -XPOST 'http://localhost:9200/_scripts/partySearch?pretty' --data "@partySearch-template.dsl"
Now that the template has been posted in we can render what search will run based on a few input parameters (due to my limited capabilities with moustache there is a redundancy match query in template - basically a query that will never match - however it should not have any performance impact).
<./dsl-queries>curl -H 'Content-Type: application/json' -XPOST 'http://localhost:9200/_render/template?pretty' --data "@partySearch-template-render.dsl"
The above request body illustrates the five possible input parameters to the partySearch search template, the first four are very similar and self explanatory (i.e. a list of names, addresses, accounts and ids). The fifth parameter determines how many characteristics of the four different types need to match before the party is considered a hit.
The last thing to do now is run the partySearch search template, and review the results.
<./dsl-queries>curl -H 'Content-Type: application/json' -XPOST 'http://localhost:9200/real-estate-sales/_search/template?pretty' --data "@partySearch-template-search.dsl"
Summary⚓︎
The above theoretical and practical walkthrough should have placed you on a solid footing when considering how to model complex data within elasticsearch, specifically the option of fulfilling event and party level analytical requirements with a single event level index.
Further Application of This Data Model⚓︎
We believe that the data model / mapping that we have used should be applicable to pretty much any domain from retail to banking. The role types and some of the details stored will obviously be different between sectors however the structure should be able to be held the same. The below table lists some examples of domains and the applicable roles for those domains to get you thinking of how you could extend the product model explained above.
| Real Estate Agent | Banking | Car Sale | Telecommunications |
|---|---|---|---|
| Event Type: | Event Type: | Event Type: | Event Type: |
| * Property Sale | * Financial Transaction | * Car Purchase | * Call |
| Roles: | Roles: | Roles: | Roles: |
| * Seller | * Payer | * Customer | * Caller |
| * Buyer | * Payee | * Sales Staff | * Number Called |
| * Buyer’s financing | * Payer Institution | * Store | * Terminating Network |
| * Buyer's solicitor | * Payee Institution | * Vehicle | * Originating Network |
| * Auctioneer | * Agent | * Insurance Company | * Transit Network |
| * Real estate Agent | |||
| * Property being sold |